Running AI Models on AKS with the Kubernetes AI Toolchain Operator

On November 15th (2023) Microsoft released kaito - the Kubernetes AI toolchain operator. This is an initial release so it's fair to say things will change over time. However, this initial release is nothing short of awesome and has great potential for the future.
The promise
Let's start with the fact: not everyone is using OpenAI or Azure Open AI Services. There is a world of alternative models out there that are not available on Azure Open AI Services. Models with different target audiences and different use cases (if you're interested check https://huggingface.co/).
Running these models require compute. Usually very expensive compute that you don't want to have provisioned, waiting for you to use it. Sometimes you simply want to use a model for a specific time period.
Then we have capacity requirements, on Public Clouds (Azure in this use case), you are required to have the capacity available before you can provision such compute. Availability for hardware that can run these models differs per region. And across regions, prices can differ as well. On top of that we also have the technical complexity of configuring machines and hardware to support these deployments.
That is where kaito comes in. Kaito is an operator that allows us to auto-provision GPU nodes for Kubernetes based on the model requirements we pass it. It takes away the complexity of tuning deployment parameters and in the end, greatly simplifies AI model deployment.
Who would have thought Kubernetes would be the way to simplify something eh?
The Tech
We can go through the exact steps to deploy kaito but fortunately it is explained very well here: https://github.com/Azure/kaito
Kaito uses workload identity to interact with your Azure resources (in this case to provision a node pool with according to the model requirements. For this to work we deploy two Helm charts:
- Helm chart for the workspace CRDs and the deployment for the workspace controller
- Helm chart for the Karpenter CRDs and the deployment of the GPU provisioner
Kaito uses Karpenter, awesome!
If you're going through the GitHub readme you will see a series of commands to populate the values file of gpu-provisioner/values.yaml. If you are running these commands from PowerShell or do not have the correct tooling install in your bash environment you will have to manual edit this file and provide it with the correct values like so:
.... Redacted for readability
env:
- name: ARM_SUBSCRIPTION_ID
value: <Your SUB ID>
- name: LOCATION
value: westeurope
- name: AZURE_CLUSTER_NAME
value: aks-wesh-kaito
- name: AZURE_NODE_RESOURCE_GROUP
value: MC_rg-aks-kaito_aks-wesh-kaito_westeurope
- name: ARM_RESOURCE_GROUP
value: rg-aks-kaito
.... Redacted for readability
workloadIdentity:
clientId: "<Your Workload identity client ID>"
tenantId: "<Your Tenant ID>"
Adjust accordingly.
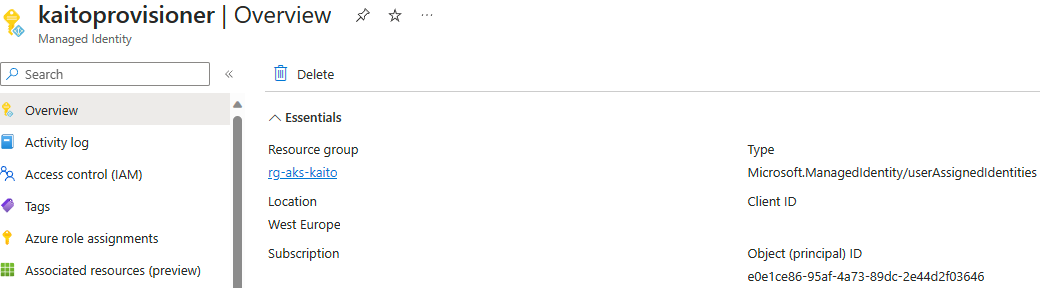
Note: If you followed the Readme and have issues finding the Client ID for the Workload Identity, check the Azure Portal and look for the "kaitoprovisioner" managed identity, it should have the information you need.
Deploying a model
With everything installed we can deploy a model. We do so by deploying a workspace. The kaito repository comes with a series of examples, we will be using the falcon-7b example. Why? Because that fits the capacity quota I have 😄
apiVersion: kaito.sh/v1alpha1
kind: Workspace
metadata:
name: workspace-falcon-7b
annotations:
kaito.sh/enablelb: "True"
resource:
instanceType: "Standard_NC12s_v3"
labelSelector:
matchLabels:
apps: falcon-7b
inference:
preset:
name: "falcon-7b"We're deploying something of kind "Workspace", as this fits the CRDs that come with the Helm chart. Most importantly here is that we specify an instanceType which will tell the gpu-provisioner what type of compute we need for this model.
Next, we kubectl apply this thing! (kubectl apply -f .\kaito_workspace_falcon_7b.yaml)
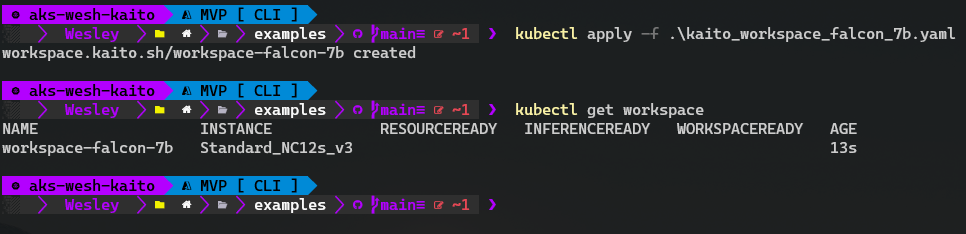
And now we wait! In the background the gpu-provisioner is creating a new node pool with a machine of SKU Standard_NC12s_v3. As we are impatient, let's take a little peek at the Azure Portal.
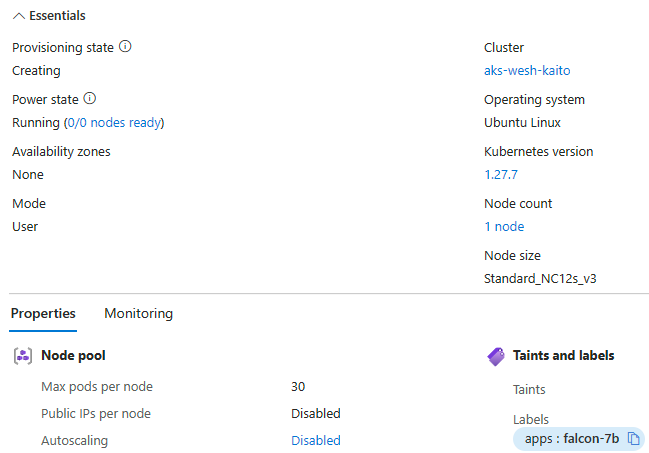
As we can see the provision process started! A node for our flacon-7b model is now being deployed. Rather sooner than later the command kubectl get workspace will tell you that the resource "workspace-faclon-7b" is ready. However, we need to wait for the model to be ready for inferencing (accepting our requests and produce output). This basically means you're waiting for the container image to be pulled and the pod to be started.
Once the model is ready for inferencing we can feed it some information. To do so we need to grab the IP address as provided by the service for our workspace:
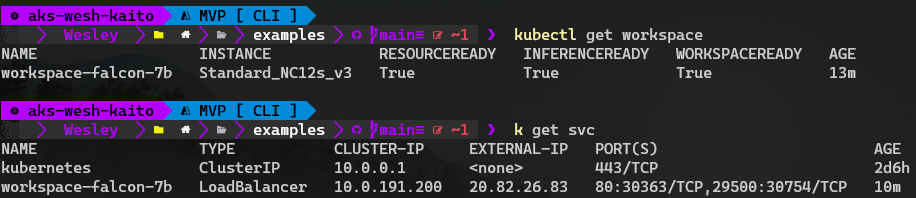
And there we have it, we can now "communicate" with our newly deployed model by using either CURL or build our own frontend interface.

Cleaning up
But what if we're done with the model and did the work we wanted to do? We don't want to leave that expensive piece of compute running as that will increase our Azure spend significantly. And if we're not using it, we don't want that.
We can simply delete our workspace by running kubectl delete -f .\kaito_workspace_falcon_7b.yaml and this will also trigger the gpu-provisioner to delete our expensive node pool!

As deletions happen quicker than creation, we can verify by checking the node pools on our cluster or inspecting our activity log to confirm the node pool is no longer there:
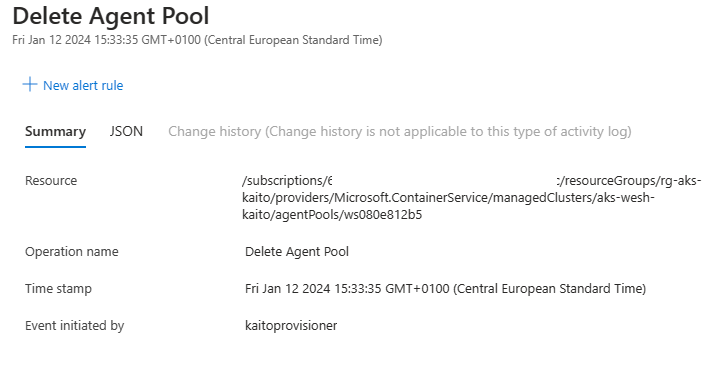
There we go, all cleaned up.
Wrap up
Being able to manage the lifecycle of the GPU compute like this provides a world of options in the scaling of our model deployments (across regions if needed) or for the temporary use of models in our DevOps processes.
Obviously, we are using the very first version of kaito that is available, and the solution is still very new. But with the technologies it leverages and increasing popularity of Cloud Native and AI, this is a very exciting and promising start for kaito!